"Kỳ lân" Zhipu AI phát triển mô hình giống GPT-4o tại Trung Quốc
Mô hình trực quan mới nhất của kỳ lân AI Trung Quốc có thể đọc và hiểu nội dung cả video lẫn trang web…

Zhipu AI là nhà cung cấp thị trường LLM lớn thứ ba ở Trung Quốc theo International Data Corporation.
Kỳ lân AI Trung Quốc, Zhipu AI, đang tăng tốc nhằm giành vị trí dẫn đầu cuộc đua trí tuệ nhân tạo đa phương thức. Hồi tháng 7, công ty chính thức ra mắt Zhipu Qingying, mô hình tạo video tương tự như Sora, theo Kr Asia.
Sora của OpenAI được giới chuyên gia đánh giá là công cụ AI tạo sinh cho ra những thước phim chất lượng tốt nhất hiện nay. Tuy nhiên, sau nhiều tháng ra mắt, Sora vẫn không thể truy cập, còn Qingying cung cấp tài khoản sử dụng miễn phí cho công chúng từ ngày đầu xuất hiện.
Một tháng sau, vào ngày 29 tháng 8, Zhipu trở thành tâm điểm tại Hội nghị Quốc tế Phát hiện và Khai thác Kiến thức (KDD) với việc ra mắt "Her", mô hình tương tự GPT-4o. Sản phẩm được công ty khẳng định là hướng tới người tiêu dùng Zhipu Qingyan bởi sở hữu chức năng "gọi video" mới có tích hợp AI, tiến gần hơn đến khả năng giao tiếp giống con người.
Ngoài ra, Qingyan cũng cập nhật xu hướng khá nhanh. Sau khi trò chơi Black Myth: Wukong nổi tiếng, mô hình nhanh chóng hiểu và có thể bàn luận với người dùng.
Bên cạnh cập nhật trên, Zhipu còn tung ra bộ mô hình đa phương thức mới, bao gồm mô hình trực quan GLM-4V-Plus (cả video và trang web) và mô hình chuyển văn bản thành hình ảnh CogView-3-Plus.
Mô hình ngôn ngữ cơ bản GLM cũng được nâng cấp lên GLM-4-Plus, có khả năng xử lý văn bản dài và giải quyết vấn đề toán học phức tạp một cách dễ dàng.
Trợ lý giúp làm bài tập về nhà, gia sư và công việc bếp
Trước đây, GPT-4o khiến người dùng trầm trồ với khả năng dự đoán cảm xúc. Nhưng Qingyan có cách tiếp cận đơn giản hơn. Khi bắt đầu sử dụng, mô hình nhắc nhở người dùng rằng, là một AI, chúng sẽ không thể hiện cảm xúc.
Điều đó cho thấy, tính năng gọi video của Qingyan có nhiều ứng dụng thực tế, phù hợp với chủ trương của Trung Quốc về học tập suốt đời.
Chẳng hạn, khi công cụ trở thành gia sư tiếng Anh cá nhân, người dùng có thể bật camera và học theo yêu cầu, mọi lúc, mọi nơi. Hay khi Qingyan là giáo viên toán, lời giảng của công cụ sánh ngang với gia sư ngoài đời thực, hỗ trợ rất nhiều cho bậc phụ huynh.
Tại nhà, Qingyan đóng vai trò là trợ lý cá nhân. Chúng có thể phân biệt túi cà phê và cung cấp thông tin ngắn gọn lịch sử thương hiệu. Mặc dù đôi khi có chút sai sót, như công cụ gợi ý cách bảo quản túi thay vì cà phê bên trong.
Mô hình trực quan mới: Từ hiểu video đến diễn giải mã
Tại KDD, Zhipu AI công bố bản cập nhật bao gồm thế hệ mới của mô hình ngôn ngữ cơ sở và đa phương thức nâng cao: GLM-4V-Plus và CogView-3-Plus.
Đáng chú ý, GLM-4-Plus được đào tạo bằng dữ liệu tổng hợp chất lượng cao, chứng minh dữ liệu do AI tạo ra cực kỳ hiệu quả trong việc đào tạo mô hình và giảm chi phí. Theo Zhipu AI, khả năng hiểu ngôn ngữ của GLM-4-Plus ngang bằng với một số đối thủ như GPT-4o và Llama3.1-405B.
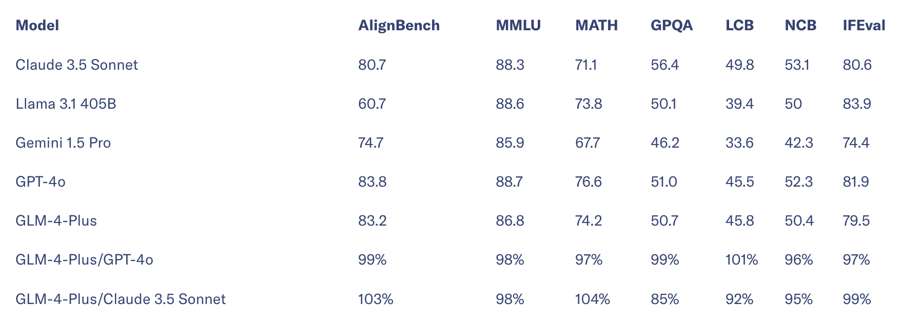
Bảng điểm chuẩn toàn diện một số mô hình ngôn ngữ lớn.
Về khả năng xử lý văn bản dài, GLM-4-Plus hoạt động ngang với GPT-4o và Claude 3.5 Sonnet. Trên bộ thử nghiệm InfiniteBench, được tạo ra bởi nhóm của Liu Zhiyuan tại Đại học Thanh Hoa, GLM-4-Plus thậm chí còn vượt trội hơn một chút so với các mô hình hàng đầu hiện nay.
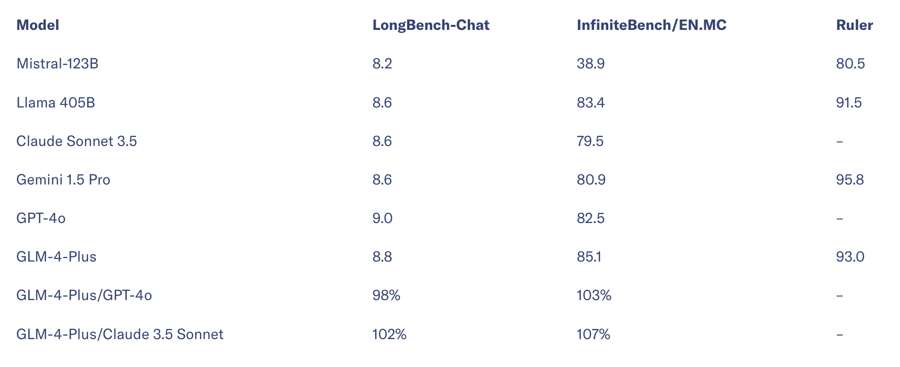
Bảng tiêu chuẩn mô hình hóa văn bản dài.
Hơn nữa, bằng cách tối ưu hóa chính sách gần đúng (PPO) - phương pháp tăng khả năng ra quyết định trong nhiều nhiệm vụ phức tạp - GLM-4-Plus có thể suy luận dữ liệu phù hợp hơn với sở thích con người.
Chi phí xử lý cho 1 triệu mã thông báo bằng GLM-4-Plus là 7 USD, tương đương với mô hình lớn mới nhất của Baidu, Ernie 4.0 Turbo, có giá khoảng 4,2 USD cho đầu vào và 8,4 USD 8,4 cho đầu ra trên một triệu mã thông báo.
Tuy nhiên, điều thực sự mang tính đột phá nằm ở khả năng đa phương thức.
Giờ đây, mô hình trực quan mới GLM-4V-Plus có thể hiểu nội dung video và trang web, đây là cải tiến đáng kể so với phiên bản tiền nhiệm.
Khác với một số mô hình thông thường, GLM-4V-Plus không chỉ hiểu các video phức tạp mà còn ghi nhớ cả thời gian. Người dùng có thể hỏi về khoảnh khắc cụ thể trong video và công cụ sẽ xác định chính xác nội dung. Tuy nhiên, tính đến thời điểm hiện tại, nền tảng mở của Zhipu AI vẫn chưa hỗ trợ tải video lên cho tính năng này.
Mặc dù có khả năng trực quan ấn tượng, GLM-4V-Plus vẫn hụt hơi trong đa số cuộc đối thoại dài và hiểu văn bản, có nghĩa là vẫn chưa ngang bằng GPT-4o ở mặt này.
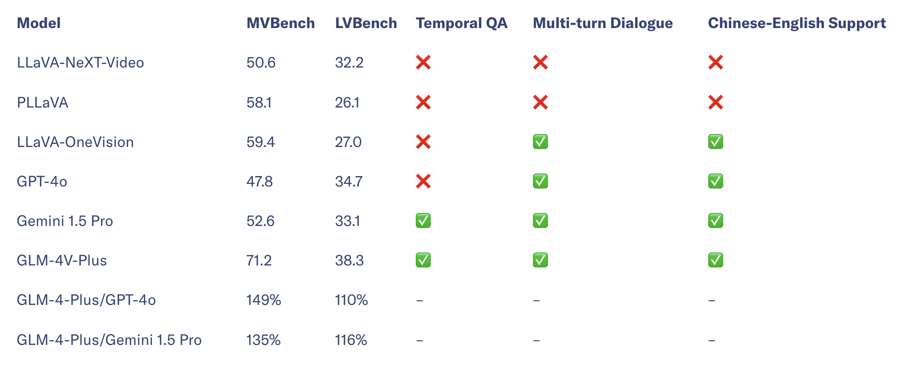
Bảng tiêu chuẩn hiểu năng lực video.
Tại KDD, Zhipu AI cũng giới thiệu CogView-3-Plus, thế hệ tiếp theo của mô hình chuyển văn bản thành hình ảnh. So với FLUX, người tiên phong trong lĩnh vực này, CogView-3-Plus có thể tạo ra hình ảnh trong vòng 20 giây, đồng thời hỗ trợ chỉnh sửa hình ảnh, chẳng hạn như thay đổi màu sắc đối tượng hoặc thay thế các mục trong hình ảnh.
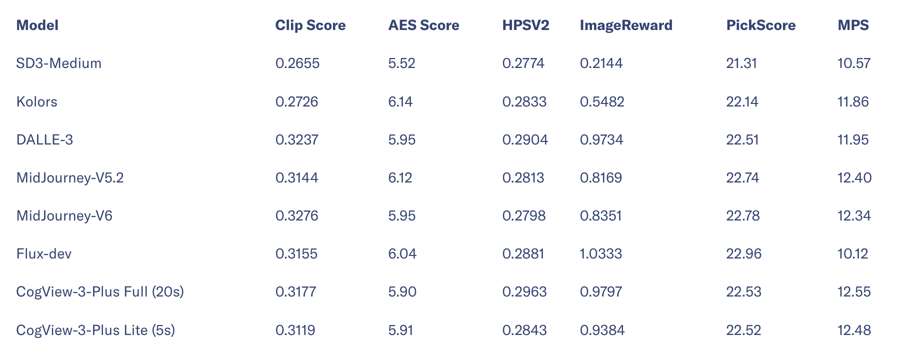
Bảng tiêu chuẩn năng lực chuyển văn bản thành hình ảnh.
Zhipu AI mất hơn bảy tháng để thêm hậu tố "Plus" vào các mẫu ra mắt từ tháng 1/2024, chu kỳ phát triển dài nhất kể từ năm 2023.
Hầu hết công ty AI của Trung Quốc đang áp dụng chiến lược chia để trị (giải quyết vấn đề lớn bằng cách chia thành nhiều vấn đề nhỏ), trước tiên là tăng cường khả năng đơn phương thức trước khi giải quyết thách thức về tích hợp. Zhipu AI vẫn đang trong giai đoạn này, sự ra mắt tính năng gọi video là thời điểm đầu trong phản ứng tổng hợp đa phương thức.
 Fed gióng hồi chuông cảnh báo về mô hình AI Mythos của Anthropic nhưng phải chờ nhiều tháng mới được tiếp cận
Fed gióng hồi chuông cảnh báo về mô hình AI Mythos của Anthropic nhưng phải chờ nhiều tháng mới được tiếp cận

 Super Micro tăng vọt 15% nhờ các đơn hàng mới và việc tiết lộ biên lợi nhuận sau thông báo từ SpaceX
Super Micro tăng vọt 15% nhờ các đơn hàng mới và việc tiết lộ biên lợi nhuận sau thông báo từ SpaceX
 Các nhà nghiên cứu Iran phát triển tua-bin gió không cánh cho khu vực gió yếu, đổi hướng liên tục
Các nhà nghiên cứu Iran phát triển tua-bin gió không cánh cho khu vực gió yếu, đổi hướng liên tục

 Australia xây dựng bộ tiêu chuẩn AI quốc gia, tăng cường quản trị và phát triển có trách nhiệm
Australia xây dựng bộ tiêu chuẩn AI quốc gia, tăng cường quản trị và phát triển có trách nhiệm