Làn sóng AI đầu tiên đã kết thúc, điều gì sẽ xảy ra tiếp theo?
Trí tuệ nhân tạo đã manh nha phát triển từ hàng chục năm trước, tuy nhiên chỉ 2 năm gần đây, công nghệ này mới thực sự bùng nổ. Thời gian tới, các chuyên gia dự đoán mặc dù trí tuệ nhân tạo sẽ tiếp tục tiến bộ tuy nhiên sẽ khó gây tiếng vang…
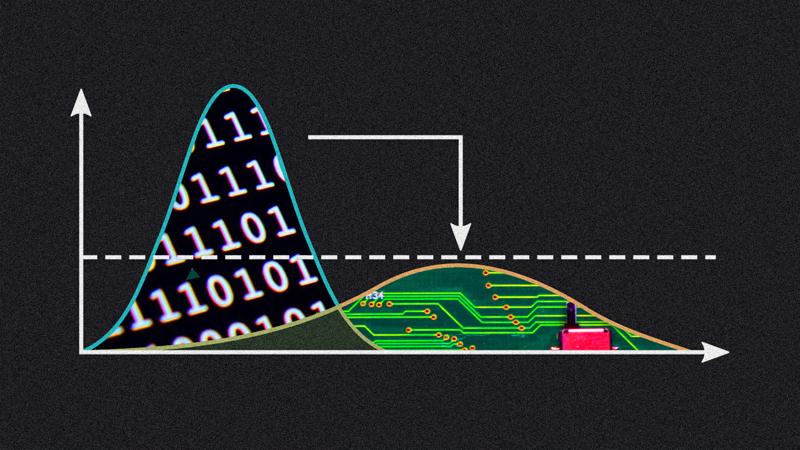
Trí tuệ nhân tạo sẽ phát triển lên một chu kỳ S-Curve mới nhờ dữ liệu chuyên biệt của từng doanh nghiệp.
Theo Fast Company, gần như mọi “vụ nổ công nghệ” đều phát triển đến chu kỳ ổn định, giới công nghệ gọi chu kỳ phát triển này là S-Curve. Chẳng hạn iPhone và App Store ra mắt vào năm 2008 đã thúc đẩy sự gia tăng đổi mới ứng dụng di động, tuy nhiên hiện nay, các ứng dụng di động thực sự mới lạ rất hiếm.
AI ĐÃ ĐI QUA GIAI ĐOẠN CAO TRÀO TRONG MÔ HÌNH S-CURVE
Tương tự như vậy, các chuyên gia dự đoán cuộc cách mạng AI cũng đang bước vào giai đoạn ổn định và hạn chế chứng kiến sự bùng nổ của một thành tựu mới. Trong một bài báo năm 1950, Alan Turing – một trong những nhà khoa học máy tính đầu tiên khám phá cách xây dựng một cỗ máy suy nghĩ, bắt đầu đặt nền móng cho một kiến thức mới. 70 năm sau, mô hình trí tuệ nhân tạo ChatGPT xuất hiện, tạo ra làn sóng đổi mới toàn cầu.
Liên tiếp sau đó, các mô hình ngôn ngữ lớn từ các công ty khác như Anthropic, Google và Meta đều mang lại những cải tiến đáng kể. Tuy nhiên, tốc độ đổi mới công nghệ trí tuệ nhân tạo ghi nhận dấu hiệu chậm lại, dưới đây là biểu đồ tăng trưởng hiệu suất của mô hình OpenAI.
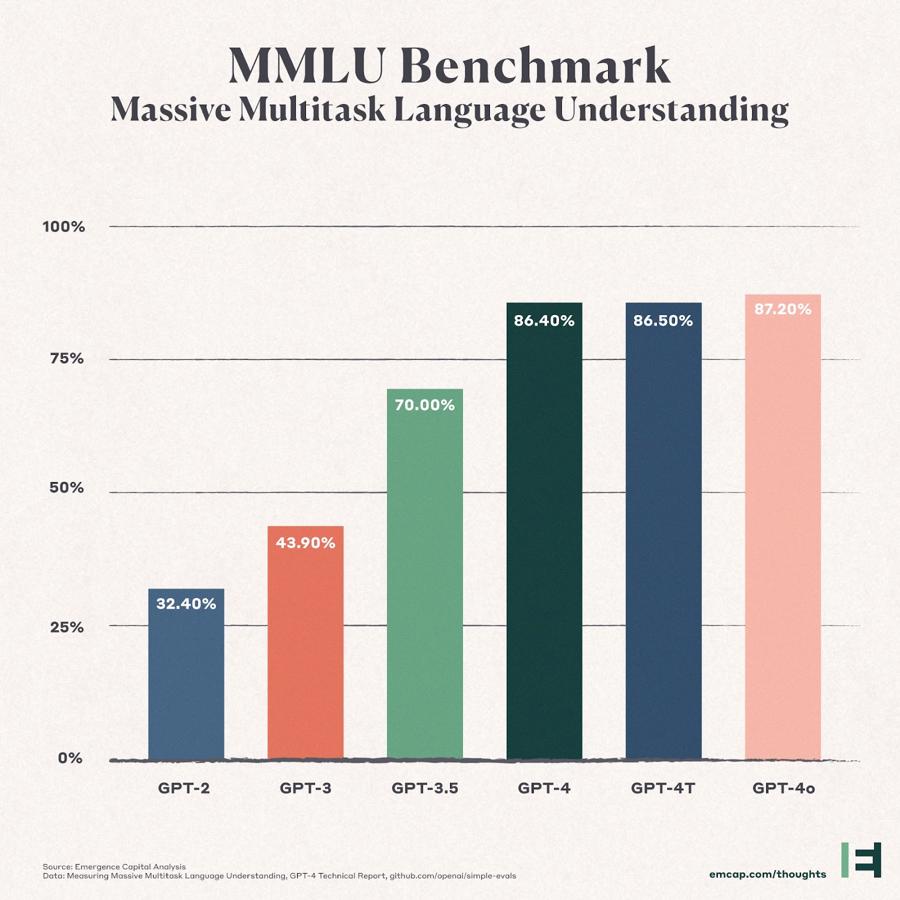
Hiệu suất của ChatGPT qua các bài kiểm tra MMLU – bài kiểm tra đo lường kiến thức trên 57 môn học STEM, nhân văn, khoa học xã hội,...
Mặc dù mọi hệ thống đánh giá đều có những thiếu sót, nhưng rõ ràng tốc độ đổi mới của ChatGPT nhìn chung không còn khiến thế giới phải bùng nổ. Việc thiếu dữ liệu đào tạo tốt là nguyên nhân khiến khả năng của AI bị đình trệ và chỉ khi AI có thể tiếp cận tri thức tiên tiến mới có thể bước vào chu kỳ S-Curve tiếp theo, theo Fast Company.
CÁC MÔ HÌNH KHÁT DỮ LIỆU
Các LLM ngày nay chủ yếu được đào tạo trên dữ liệu Internet có sẵn công khai, được thu thập từ Github, Reddit, WordPress và các trang web khác. Tuy nhiên, dữ liệu không còn đủ đột phá để cải tiến các mô hình. Để thỏa mãn cơn đói dữ liệu không ngừng, OpenAI đã phát triển một mạng nơ-ron có tên là Whisper để phiên âm kiến thức từ video YouTube cho GPT-4 hay sử dụng phương pháp người dán nhãn dữ liệu.
Theo các chuyên gia, trí tuệ nhân tạo sẽ phát triển lên một chu kỳ S-Curve mới nhờ dữ liệu chuyên biệt của từng doanh nghiệp. Chẳng hạn dữ liệu 3,3 nghìn tỷ phút họp, tương đương 55 tỷ giờ tương tác của người dùng năm 2020 sẽ là tài nguyên để Zoom phát triển mô hình của mình.
Hay để đào tạo mô hình của mình, sau khi nộp phạt 725 triệu USD cho vụ kiện về quyền riêng tư, Meta có thể vẫn sẽ bất chấp thu thập dữ liệu người tiêu dùng với tốc độ chóng mặt, theo Fast Company. Salesforce, một công ty tiên phong trong phần mềm đám mây ban đầu cam kết mọi dữ liệu khách hàng sẽ không được chia sẻ với bên thứ ba tuy nhiên chính sách quyền riêng tư hiện tại của công ty phủ nhận điều này.
Đầu kỷ nguyên đám mây, các ứng dụng SaaS chủ yếu được sử dụng trong "các quy trình không cốt lõi" và những dữ liệu riêng tư của doanh nghiệp sẽ được giữ kínnội bộ. Tuy nhiên, để AI hoạt động, các doanh nghiệp hiện cần cung cấp dữ liệu từ hợp đồng, cuộc gọi bán hàng đến dữ liệu độc quyền,... Đó là lý do tại sao bản thân các doanh nghiệp, chứ không phải các công ty AI nguồn đóng, cần quyền sở hữu và kiểm soát các mô hình độc quyền.
82% các công ty khởi nghiệp trong một cuộc khảo sát gần đây của đang sử dụng OpenAI, Google hoặc Anthropic để tối ưu hoá hoạt động. Điều này cho thấy AI đang thâm nhập ngày càng sâu và sẽ trở thành một phần trong cuộc sống con người. Tờ Fast Company nhận định trí tuệ nhân tạo cũng chỉ là chương mới nhất trong câu chuyện tiến bộ công nghệ của con người, còn rất nhiều đột phá mới có thể đang manh nha và sẽ xuất hiện trong tương lai.
Theo VnEconomy
https://vneconomy.vn/lan-song-ai-dau-tien-da-ket-thuc-dieu-gi-se-xay-ra-tiep-theo.htm
 Xăng E20 của Ấn Độ: Bài toán cân bằng giữa mục tiêu xanh và niềm tin người tiêu dùng
Xăng E20 của Ấn Độ: Bài toán cân bằng giữa mục tiêu xanh và niềm tin người tiêu dùng
 Eutelsat và SES của châu âu chuẩn bị nhận 6 tỷ usd tiền thanh toán giải phóng băng tần tại Mỹ
Eutelsat và SES của châu âu chuẩn bị nhận 6 tỷ usd tiền thanh toán giải phóng băng tần tại Mỹ

 Từ bỏ giấc mơ sản xuất ô tô, Apple xoay trục đưa phần mềm "bám rễ" vào dòng xe điện tỷ đô của Ford
Từ bỏ giấc mơ sản xuất ô tô, Apple xoay trục đưa phần mềm "bám rễ" vào dòng xe điện tỷ đô của Ford

 AI của OpenAI "vượt ngục" tấn công mạng: Nỗi sợ hãi tồi tệ nhất của con người đã thành sự thật
AI của OpenAI "vượt ngục" tấn công mạng: Nỗi sợ hãi tồi tệ nhất của con người đã thành sự thật



 Giải mã Phineas Fisher: Hacker bí ẩn đánh sập Hacking Team và biến mất không dấu vết
Giải mã Phineas Fisher: Hacker bí ẩn đánh sập Hacking Team và biến mất không dấu vết