xAI có nói dối về điểm chuẩn của Grok 3 không?
Cuộc tranh cãi về tính minh bạch trong báo cáo hiệu suất AI đang nóng lên khi OpenAI và xAI của Elon Musk đối đầu trực tiếp.
Mọi chuyện bắt đầu khi một nhân viên OpenAI tố cáo xAI công bố kết quả chuẩn mực "méo mó" cho Grok 3 – mô hình AI mới nhất của họ.
Trong báo cáo, xAI đăng biểu đồ so sánh Grok 3 Reasoning Beta và Grok 3 mini Reasoning vượt trội o3-mini-high của OpenAI trên bộ AIME 2025 – tập hợp bài toán khó từ kỳ thi Toán học Mời Hoa Kỳ. Tuy nhiên, chi tiết then chốt bị che khuất: OpenAI sử dụng phương pháp cons@64 (thống nhất 64 lần thử) để tối ưu điểm số, trong khi xAI chỉ công bố kết quả ở lần thử đầu tiên.
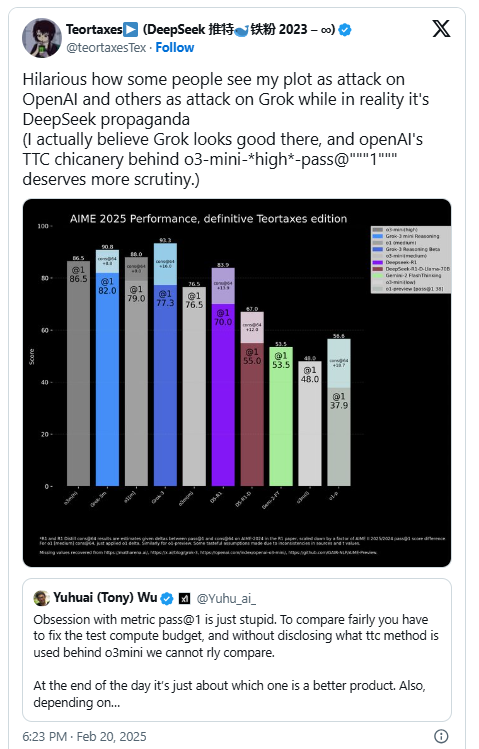
Bức tranh trở nên phức tạp khi phân tích sâu: Ở chế độ @1 không tối ưu, Grok 3 thực sự đạt điểm thấp hơn đối thủ. Đáng chú ý, tốc độ xử lý của Grok 3 Reasoning Beta còn chậm hơn cả phiên bản tiêu chuẩn o1 của OpenAI.
Dù vậy, xAI vẫn quảng cáo Grok 3 là "AI thông minh nhất thế giới". Đáp trả, đồng sáng lập xAI Igor Babushkin chỉ ra rằng chính OpenAI từng sử dụng thủ thuật tương tự khi so sánh các phiên bản nội bộ, biến cuộc tranh luận thành trận đấu "gậy ông đập lưng ông".
Giới chuyên gia như Nathan Lambert chỉ ra vấn đề cốt lõi: Các chuẩn mực AI hiện tại đang bỏ qua yếu tố then chốt – chi phí tính toán và hiệu quả tài nguyên.
Liệu thành tích ấn tượng có đến từ thuật toán vượt trội hay đơn thuần là đốt tiền đầu tư phần cứng? Câu hỏi này vẫn bỏ ngỏ, phơi bày nghịch lý trong ngành AI: Những con số hào nhoáng đôi khi che khuất thước đo thực sự về năng lực hệ thống
 Australia xây dựng bộ tiêu chuẩn AI quốc gia, tăng cường quản trị và phát triển có trách nhiệm
Australia xây dựng bộ tiêu chuẩn AI quốc gia, tăng cường quản trị và phát triển có trách nhiệm

 Thẩm phán Mỹ phê duyệt thỏa thuận hòa giải 1,5 tỷ USD của Anthropic trong vụ kiện bản quyền
Thẩm phán Mỹ phê duyệt thỏa thuận hòa giải 1,5 tỷ USD của Anthropic trong vụ kiện bản quyền

 Nhu cầu về điện và nước thử thách nỗ lực xây dựng trung tâm chip AI ngoài Seoul của Hàn Quốc
Nhu cầu về điện và nước thử thách nỗ lực xây dựng trung tâm chip AI ngoài Seoul của Hàn Quốc
 Các hãng sản xuất chip hướng tới mức tăng lợi nhuận lớn, nhưng liệu như vậy đã đủ?
Các hãng sản xuất chip hướng tới mức tăng lợi nhuận lớn, nhưng liệu như vậy đã đủ?
 Trung Quốc và Thái Lan hướng tới hợp tác công nghệ sâu rộng hơn để thúc đẩy "tương lai chung thịnh vượng"
Trung Quốc và Thái Lan hướng tới hợp tác công nghệ sâu rộng hơn để thúc đẩy "tương lai chung thịnh vượng"
 Google lên kế hoạch sản xuất chip mới để vận hành các mô hình Gemini hiệu quả hơn, theo báo cáo từ The Information
Google lên kế hoạch sản xuất chip mới để vận hành các mô hình Gemini hiệu quả hơn, theo báo cáo từ The Information

 Ủy ban thuộc Quốc hội Pháp thông qua lệnh cấm mạng xã hội đối với trẻ dưới 15 tuổi
Ủy ban thuộc Quốc hội Pháp thông qua lệnh cấm mạng xã hội đối với trẻ dưới 15 tuổi