Dữ liệu - Từ mỏ dầu đến động lực cạnh tranh trong kỷ nguyên AI
Nghị quyết 57-NQ/TW của Bộ Chính trị và Luật Dữ liệu khẳng định dữ liệu là “tư liệu sản xuất mới”, là tài nguyên chiến lược cần được huy động nguồn lực để phát triển thành tài sản. Để hiện thực hóa chủ trương của Đảng, luật của Quốc hội, Chính phủ đã ban hành đồng bộ các văn bản (Nghị định số 278, Nghị quyết số 175 và 214); tập trung xây dựng Trung tâm dữ liệu quốc gia hiện đại; khung kiến trúc dữ liệu quốc gia thống nhất; thúc đẩy tạo lập dữ liệu, quy định về kết nối, chia sẻ dữ liệu thống nhất trong toàn hệ thống chính trị để hình thành nền tảng dữ liệu quốc gia hiện đại, tin cậy, hiệu quả. Mục tiêu đến năm 2030 là thay thế trên 90% hoạt động hành chính bằng xử lý dữ liệu số.
Kết luận phiên họp Ban Chỉ đạo quốc gia về dữ liệu, Thủ tướng Phạm Minh Chính nhấn mạnh, cần phát triển dữ liệu, kinh tế dữ liệu với những đột phá và cải cách mạnh mẽ, toàn diện hơn nữa để Việt Nam bắt kịp, tiến cùng và vươn lên trên các lĩnh vực, là động lực quan trọng góp phần tăng trưởng 2 con số thời gian tới, Thủ tướng nêu rõ 5 đột phá chiến lược về dữ liệu số, với tinh thần "đúng, đủ, sạch, sống, liên thông, thống nhất, dùng chung" và phương châm "quyết tâm, quyết liệt, trọng tâm, trọng điểm, hiệu quả, bao trùm, bền vững, vì dân".

Thủ tướng Phạm Minh Chính. Ảnh: VGP/Nhật Bắc.
Trong vài năm trở lại đây, thêm thuật ngữ “dữ liệu là mỏ dầu mới của thế kỷ 21” được nhắc đến ngày càng nhiều trong những bài thuyết trình, báo cáo chiến lược của doanh nghiệp và chính sách của nhà nước. Vậy dữ liệu là gì? Dữ liệu từ đâu? AI sử dụng nó như nào? Chúng ta cùng đi qua nội dung dưới đây.
Dữ liệu là gì?
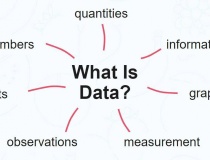
Trước hết, chúng ta cần hiểu, dữ liệu không phải là một thứ mơ hồ. Dữ liệu là tập hợp các thông tin, sự kiện, con số, mô tả và mô hình biểu diễn thế giới thật dưới dạng mà máy tính có thể xử lý. (Theo Wikipedia). Nó là bản ghi lịch sử, cái được ghi lại khi một sự kiện xảy ra, một hành động được thực hiện, một quan sát được thực hiện. Khi một người dùng truy cập website, đó là một đơn vị dữ liệu. Khi một cảm biến đo nhiệt độ, đó là một đơn vị dữ liệu. Khi một nhân viên gõ vào khung chat nội bộ của công ty, đó lại tiếp tục là dữ liệu.
Dữ liệu không chỉ là những con số phức tạp; nó đồng thời là văn bản, hình ảnh, video, âm thanh, tương tác người dùng và ngay cả những phản hồi rất nhỏ như click chuột hay di chuyển con trỏ trên màn hình. Dữ liệu phản ánh hoạt động của con người, của máy móc, của môi trường tự nhiên, của kinh tế và của xã hội. Khi chúng ta nói “dữ liệu là tài sản”, chúng ta đang nói đến khả năng chuyển đổi những ghi chép này thành kiến thức, hành động, quyết định và lợi thế cạnh tranh.
Dữ liệu là gì.
Nguồn gốc dữ liệu - Nó đến từ đâu?
Dữ liệu có thể đến từ vô số nguồn, nhưng ở mức độ tổng quát, chúng ta có thể hình dung nó sinh ra từ bốn “nguồn lực” cơ bản: con người, máy móc, hệ thống kinh doanh và môi trường tự nhiên.
Đầu tiên là dữ liệu do con người tạo ra. Đây là dữ liệu xuất phát từ hành vi, quyết định, phản hồi, tương tác và ngôn ngữ của con người. Ví dụ, mỗi lần chúng ta sử dụng ứng dụng mạng xã hội, mỗi email gửi đi, mỗi xử lý văn bản, mỗi cuộc trò chuyện tất cả các hành động này tạo ra những bản ghi dữ liệu nhỏ bé. Khi tích lũy hàng triệu, hàng tỷ bản ghi như vậy, ta có một kho dữ liệu về hành vi, ngôn ngữ và tương tác rất phong phú.
Thứ hai là dữ liệu đến từ máy móc và cảm biến. Trong thế giới ngày nay, mọi thiết bị đều có thể là nguồn dữ liệu: camera an ninh ghi hình 24/7, cảm biến đo nhiệt độ, áp lực, độ ẩm, các thiết bị IoT gửi thông số định kỳ, hệ thống vận hành IT ghi lại log, server ghi lại trạng thái hoạt động. Dữ liệu máy móc mang tính hoàn toàn khác biệt so với dữ liệu con người: nó thường ở dạng số, đo lường chính xác, và có thể có tần suất cao đến mức dữ liệu “chảy như nước”.
Thứ ba là dữ liệu từ hệ thống kinh doanh. Đây là dữ liệu nội bộ doanh nghiệp, hóa đơn, đơn đặt hàng, hồ sơ khách hàng, lịch sử giao dịch, CRM, ERP, dữ liệu sản xuất, tồn kho... Đây là loại dữ liệu chiến lược nhất vì nó phản ánh hoạt động lõi của doanh nghiệp và thường là dữ liệu mà đối thủ không thể tiếp cận.
Cuối cùng là dữ liệu từ môi trường tự nhiên và xã hội, như dữ liệu thời tiết, dữ liệu địa lý, ảnh vệ tinh, dữ liệu giao thông… Những dữ liệu này thường do chính phủ và các tổ chức nghiên cứu thu thập, và ngày càng được sử dụng trong các mô hình AI để dự báo, phân tích và tối ưu.
Ta có thể thấy, từ các nguồn dữ liệu, nhưng trình độ cũng như khả năng hạ tầng để thu thập, lưu trữ, phân loại, xử lý, xây dựng mô hình và khai thác hiệu quả dữ liệu thì phụ thuộc rất nhiều vào chính chúng ta.
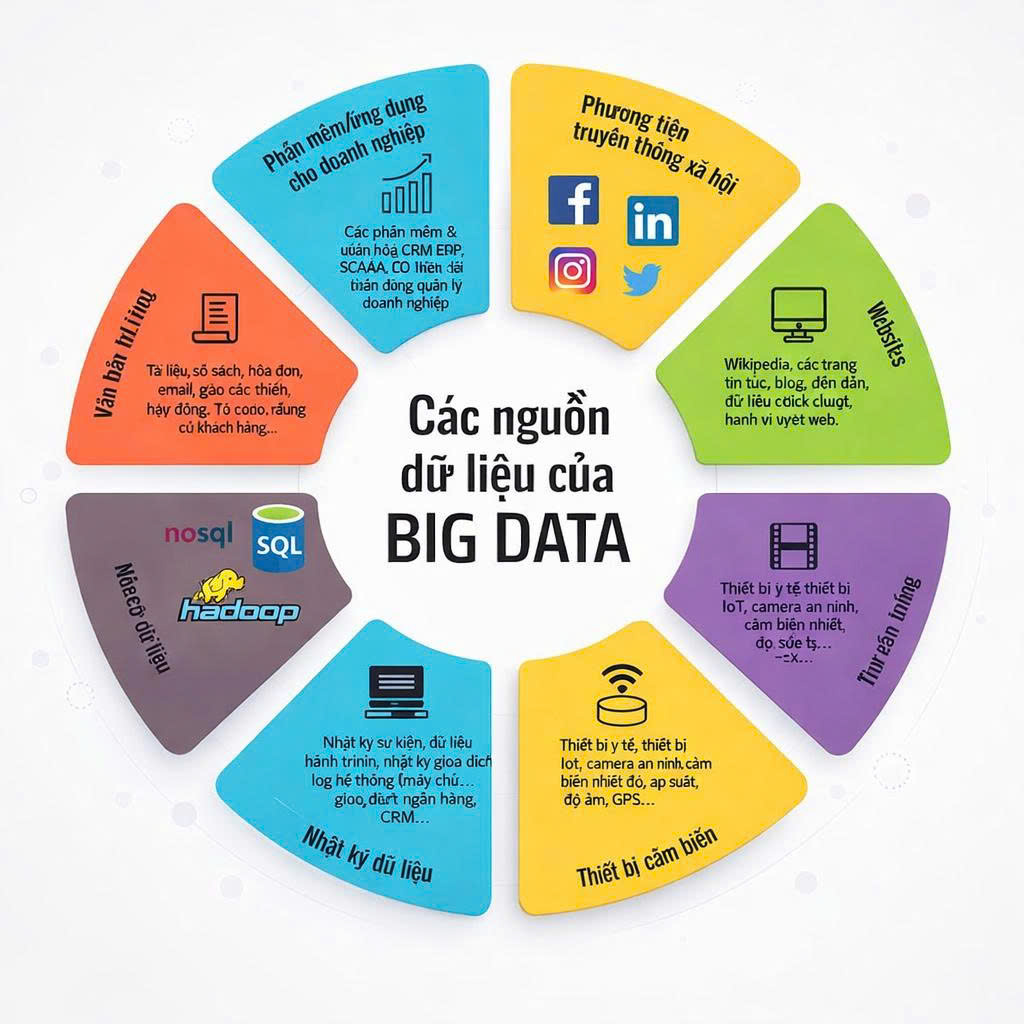
Các nguồn phát sinh dữ liệu.
Phân loại dữ liệu - Không phải dữ liệu nào cũng giống nhau
Khi hiểu dữ liệu là gì và nó đến từ đâu, bước tiếp theo là phân loại, bởi vì giá trị của dữ liệu phụ thuộc rất lớn vào loại và cấu trúc của nó.
Một trong những cách phân loại dữ liệu cơ bản nhất là theo mức độ cấu trúc. Dữ liệu có cấu trúc là dữ liệu được tổ chức theo bảng, theo hàng, theo cột, ví dụ như bảng thông tin khách hàng trong cơ sở dữ liệu. Nó dễ truy vấn, dễ xử lý bằng SQL và được hầu hết các hệ thống phân tích truyền thống sử dụng. Dữ liệu bán cấu trúc, như JSON hoặc XML, có tổ chức nhưng không tuân theo schema cố định. Đây là loại dữ liệu phổ biến trong ứng dụng web hiện đại và các dịch vụ API. Cuối cùng, dữ liệu phi cấu trúc là dữ liệu không có dạng bảng rõ ràng (văn bản, hình ảnh, video, âm thanh) chiếm phần lớn lượng dữ liệu sinh ra hàng ngày.
Một cách phân loại khác là theo nguồn và thời gian sinh ra. Dữ liệu có thể đến theo lô (batch) hoặc theo dòng (streaming), theo thời gian thực (real-time) hoặc gần thời gian thực (near real-time). Điều này quyết định cách ta lưu trữ, xử lý và sử dụng dữ liệu.
Dữ liệu cũng có thể được phân theo mức độ nhạy cảm và quyền riêng tư. Dữ liệu công khai có thể được chia sẻ rộng rãi. Dữ liệu cá nhân hoặc nhạy cảm cần phải được bảo vệ theo quy định. Trong nhiều trường hợp, việc phân loại dữ liệu theo mức độ nhạy cảm là bước cần thiết để tuân thủ pháp luật và bảo vệ quyền lợi người dùng.

Mỗi dữ liệu cần được đánh giá, phân loại.
Từ dữ liệu đến AI - Hành trình chuyển từ “nguyên liệu thô” sang “giá trị trí tuệ”
Tại sao dữ liệu lại quan trọng đến vậy đối với AI? Bởi vì AI hay cụ thể hơn là học máy không “suy nghĩ” như con người, mà học từ dữ liệu. AI cần dữ liệu để tìm ra mô hình, quy luật, mối tương quan và từ đó tạo ra dự đoán hoặc phản hồi.
Trong vài năm gần đây, đặc biệt với sự bùng nổ của Generative AI (GenAI), dữ liệu trở thành nguyên liệu không chỉ cho phân tích mà còn cho sáng tạo nội dung mới. GenAI không chỉ dựa vào dữ liệu để phân tích; nó dùng dữ liệu để “học ngôn ngữ”, tạo văn bản, tạo hình ảnh, tổng hợp thông tin, thậm chí viết mã lệnh. Việc này đòi hỏi dữ liệu có quy mô rất lớn, đa dạng và giàu bối cảnh hơn rất nhiều so với các hệ thống AI truyền thống.
Nhưng GenAI cũng đặt ra yêu cầu khác: dữ liệu không thể chỉ là thô. Nó cần được tiền xử lý, gắn nhãn, chuẩn hóa và tổ chức theo cách mà mô hình có thể hiểu được. Đây chính là lý do vì sao dữ liệu không tự động trở thành tài sản giá trị: nếu không qua quá trình xử lý, dữ liệu là một đống rác không thể khai thác.
Ai có thể xây dựng AI & GenAI?
Một hiểu lầm phổ biến là doanh nghiệp hoặc tổ chức nào cũng có thể “xây AI riêng”. Trên thực tế, AI nền tảng ở mức độ GenAI (như GPT, Gemini, Claude…) đòi hỏi tài nguyên khổng lồ: hàng trăm triệu đến hàng tỷ tham số, cơ sở dữ liệu petabyte, siêu máy tính hàng trăm nghìn GPU, đội ngũ nghiên cứu chuyên sâu và chi phí hàng trăm triệu đến hàng tỷ USD hàng năm. Điều này hiện chỉ nằm trong khả năng của các tập đoàn công nghệ hàng đầu như Google, OpenAI, Meta, Anthropic, Microsoft, các trung tâm nghiên cứu lớn hoặc những chính phủ có chiến lược dữ liệu quốc gia.
Trong khi đó, hầu hết các doanh nghiệp từ ngân hàng đến nhà sản xuất, từ bệnh viện đến công ty dịch vụ không nên và không cần xây một mô hình GenAI từ đầu. Thay vào đó, họ nên tận dụng các Foundation Models (mô hình nền tảng) do Big Tech hoặc tổ chức AI lớn phát triển, và sau đó tinh chỉnh (fine-tune) hoặc tích hợp dữ liệu nội bộ để tạo ra ứng dụng AI phù hợp với mục tiêu riêng.
Vậy doanh nghiệp cần làm gì? Họ cần xây một hệ thống AI ứng dụng nơi GenAI được kết nối với dữ liệu riêng, hiểu quy trình nghiệp vụ, tuân thủ bảo mật và tạo ra giá trị cụ thể. Đây là AI doanh nghiệp chứ không phải AI nền tảng.

Trung tâm dữ liệu quy mô lớn của OpenAI, Oracle và SoftBank với tổng mức đầu tư 500 tỷ USD, công suất 10 gigawatt, dự kiến hoàn thành vào cuối năm 2025.
Doanh nghiệp ứng dụng AI thực sự là làm gì?
Khi nói về AI tại doanh nghiệp, điều quan trọng là hiểu rõ rằng AI không phải là một sản phẩm độc lập “spin-off” mà là trung tâm tri thức và tự động hóa quy trình của doanh nghiệp. AI doanh nghiệp không phải là “một chatbot chung chung”, mà là một hệ thống hiểu và hỗ trợ hoạt động thực tế.
Ví dụ, trong ngân hàng, AI có thể được dùng để phân tích tín dụng tự động, phát hiện gian lận, dự đoán rủi ro và cá nhân hóa trải nghiệm khách hàng. Trong y tế, AI có thể hỗ trợ chẩn đoán hình ảnh, dự đoán diễn biến bệnh và tối ưu lịch trình điều trị. Trong sản xuất, AI giúp lập kế hoạch bảo trì dự đoán, tối ưu chuỗi cung ứng và nâng cao chất lượng sản phẩm.
Để đạt được điều đó, doanh nghiệp phải gắn AI với dữ liệu nội bộ, quy trình nghiệp vụ và hệ thống vận hành. Điều này đòi hỏi kiến trúc dữ liệu rõ ràng, khả năng truy xuất và quản lý dữ liệu hiệu quả, và cách tích hợp AI sao cho nó thực sự tạo ra giá trị thay vì chỉ là công nghệ trưng bày.
Một trong những phương pháp hiệu quả nhất hiện nay là Retrieval-Augmented Generation (RAG) tức là sử dụng khả năng truy xuất dữ liệu từ kho tri thức doanh nghiệp, rồi đưa vào mô hình GenAI để tạo ra phản hồi phù hợp với ngữ cảnh. Nhờ vậy, doanh nghiệp có thể giữ dữ liệu nhạy cảm ở hệ thống riêng và chỉ cho AI truy cập khi cần, tránh rủi ro thông tin bị lan tỏa ngoài kiểm soát.
Đồng thời, doanh nghiệp cũng thường thực hiện fine-tuning, tinh chỉnh mô hình nền tảng dựa trên dữ liệu riêng để AI “hiểu” văn hóa, quy tắc, terminologies chuyên ngành và phong cách giao tiếp của riêng tổ chức. Điều này giúp AI phản hồi chính xác hơn, phù hợp hơn và hữu ích hơn trong bối cảnh thực tế của doanh nghiệp.
Có thể ví dụ dưới góc nhìn đời thường nhưng phản ánh đúng bản chất kỹ thuật, có thể hiểu GenAI như một “bộ máy trí tuệ” đã được các tập đoàn công nghệ lớn nuôi dưỡng, huấn luyện và cho trưởng thành sẵn. Trong quá trình đó, GenAI được tiếp xúc với khối tri thức khổng lồ của nhân loại, học ngôn ngữ, logic, cách lập luận và cách giao tiếp giống con người. Khi đạt đến mức độ đủ chín để làm việc, nó được đưa ra thị trường dưới dạng dịch vụ. Doanh nghiệp hay cá nhân không tự xây dựng và nuôi GenAI từ đầu, mà “thuê” bộ máy trí tuệ này về sử dụng trong phạm vi công việc của mình. Khi ấy, GenAI sẽ làm việc với chính dữ liệu, tài liệu, quy trình và quy tắc riêng của từng “gia chủ”, vận dụng trình độ hiểu biết và mức độ trưởng thành sẵn có để giải quyết các yêu cầu cụ thể được giao.
Tuy nhiên, cũng giống như thuê nhân công trong đời thực, với GenAI thì “tiền nào của nấy”: gia chủ có thể thuê một người thợ bậc thầy, một người thợ lành nghề trung bình hay một người mới thực tập, và chất lượng kết quả sẽ phản ánh đúng trình độ của người thợ được thuê. Các mô hình GenAI khác nhau có mức độ thông minh, khả năng suy luận và hiểu ngữ cảnh khác nhau, tương ứng với chi phí sử dụng khác nhau. Vì vậy, giá trị mà AI mang lại không nằm ở việc “có AI hay không”, mà nằm ở sự kết hợp đúng giữa cấp độ trí tuệ của mô hình được thuê, chất lượng và mức độ sẵn sàng của dữ liệu nội bộ, cùng với cách doanh nghiệp tổ chức, giao việc và khai thác bộ máy trí tuệ đó cho mục tiêu cụ thể của mình.

Ví dụ các bài toán dùng AI trong ngân hàng.
Làm thế nào để dữ liệu thực sự có ý nghĩa với AI?
Một trong những câu hỏi lớn nhất mà tổ chức nào cũng phải trả lời là: “Làm sao biến dữ liệu thô thành dữ liệu hữu ích cho AI?” Dưới đây là những bước không thể thiếu:
Đầu tiên, cần chuẩn hóa và tổ chức dữ liệu. Dữ liệu phải được tập hợp vào các kho dữ liệu có cấu trúc, với định dạng nhất quán, dễ truy vấn và được tài liệu hóa rõ ràng. Data lake và data warehouse là hai kiến trúc phổ biến để lưu trữ dữ liệu đã chuẩn hóa.
Tiếp theo, dữ liệu cần được làm sạch (clean) và gắn nhãn (labeling). Dữ liệu thô rất dễ chứa lỗi, thiếu chính xác hoặc không đầy đủ. Với AI, dữ liệu gắn nhãn chất lượng cao là nền tảng để mô hình học đúng và đưa ra dự đoán chính xác.
Không kém phần quan trọng là quản trị dữ liệu và bảo mật. Dữ liệu, đặc biệt là dữ liệu cá nhân hoặc nhạy cảm cần được phân quyền truy cập, mã hóa, tuân thủ các quy định quyền riêng tư và audit rõ ràng. Một sai sót trong bảo mật dữ liệu có thể gây thiệt hại lớn về uy tín và pháp lý.
Cuối cùng, doanh nghiệp cần thiết lập feedback loop liên tục: thu nhận phản hồi từ người dùng cuối để tinh chỉnh mô hình và cải thiện hiệu suất theo thời gian. AI không phải là hệ thống “làm xong rồi quên”; nó cần cập nhật và học hỏi liên tục từ dữ liệu mới.
Hiện nay, có khá nhiều giải pháp công nghệ giúp doanh nghiệp trong việc chuẩn bị dữ liệu với các yêu cầu trên như Solix, Informatica, Collibra, Talend, Alation, IBM InfoSphere…
Với một quốc gia - dữ liệu là tài sản chiến lược
Khi một quốc gia coi dữ liệu là tài sản chiến lược, chính phủ không chỉ bảo vệ dữ liệu mà còn phải kích hoạt và xây dựng hạ tầng, chính sách và năng lực để dữ liệu được khai thác hiệu quả. Một số yếu tố quan trọng bao gồm:
Trước hết, cần xây dựng khung pháp lý rõ ràng về quyền riêng tư, bảo mật, chia sẻ dữ liệu giữa các tổ chức và giữa công ty với nhà nước. Đây là bước nền tảng để tạo niềm tin cho người dân và doanh nghiệp khi chia sẻ và sử dụng dữ liệu.
Thứ hai, cần đầu tư vào hạ tầng dữ liệu quốc gia, trung tâm dữ liệu, cloud, mạng truyền tải dữ liệu tốc độ cao và các nền tảng chia sẻ dữ liệu an toàn. Điều này giúp đảm bảo rằng dữ liệu không chỉ bị phân mảnh trong từng tổ chức mà được liên kết và sử dụng hiệu quả trên quy mô rộng.
Thứ ba, nâng cao nhận thức và năng lực nhân lực về dữ liệu và AI là yếu tố quyết định. Một đội ngũ chuyên gia dữ liệu, kỹ sư AI, và lãnh đạo hiểu dữ liệu là chìa khóa giúp quốc gia khai thác tối đa lợi ích của AI.
Cuối cùng, cần có chính sách khuyến khích doanh nghiệp đầu tư vào chuyển đổi số và sử dụng dữ liệu để tạo ra sản phẩm, dịch vụ mới. Điều này bao gồm ưu đãi thuế, quỹ R&D, chương trình hỗ trợ startup dữ liệu và AI, cũng như tiêu chuẩn quốc gia về dữ liệu mở và mở API trong khu vực công.
AI tại Việt Nam - Bối cảnh, thách thức và cơ hội
Tại Việt Nam, nhận thức về giá trị của dữ liệu và AI đang gia tăng rõ rệt trong vài năm trở lại đây, đặc biệt trong các ngành có cường độ dữ liệu cao như tài chính - ngân hàng, viễn thông, dịch vụ và khu vực công. Trong lĩnh vực ngân hàng, nhiều tổ chức đã bước đầu ứng dụng AI vào sản phẩm và vận hành: Vietcombank triển khai chatbot và phân tích gian lận giao dịch; TPBank ứng dụng trợ lý ảo và nhận diện sinh trắc học trong hệ thống LiveBank; Techcombank sử dụng AI cho chấm điểm tín dụng và cá nhân hoá dịch vụ; VPBank, VietinBank, ACB, VIB áp dụng AI trong chăm sóc khách hàng, phát hiện rủi ro và tự động hoá quy trình nội bộ. Ở lĩnh vực viễn thông, Viettel, VNPT, MobiFone sử dụng AI để tối ưu mạng lưới, phân tích hành vi thuê bao và phát hiện gian lận. Trong giáo dục, AI bắt đầu được ứng dụng vào các nền tảng học tập thích ứng, chấm bài tự động và phân tích năng lực người học tại một số trường đại học và startup EdTech. Trong hành chính công, AI được thử nghiệm trong xử lý văn bản, chatbot dịch vụ công, nhận diện khuôn mặt và biển số phục vụ an ninh - giao thông tại một số đô thị lớn; còn trong giao thông, các hệ thống camera thông minh và phân tích luồng xe đang được triển khai để hỗ trợ điều tiết và giảm ùn tắc.
Tuy vậy, bức tranh chung vẫn cho thấy nhiều thách thức mang tính nền tảng. Dữ liệu của phần lớn tổ chức vẫn phân tán, thiếu chuẩn hoá và chưa được quản trị như một tài sản chiến lược. Hạ tầng dữ liệu và tính liên thông ở cấp quốc gia còn trong quá trình hoàn thiện. Nguồn nhân lực AI và khoa học dữ liệu, đặc biệt là những người có kinh nghiệm triển khai trong bối cảnh doanh nghiệp và khu vực công, vẫn còn hạn chế. Nhận thức về AI tuy đã lan rộng ở các tập đoàn lớn, nhưng ở nhiều doanh nghiệp vừa và nhỏ, AI vẫn được nhìn nhận như một công cụ công nghệ thử nghiệm hơn là một năng lực cốt lõi dài hạn. Dẫu vậy, với các chương trình chuyển đổi số quốc gia, sự tham gia ngày càng rõ nét của cả khu vực nhà nước lẫn tư nhân, cùng hệ sinh thái startup và đào tạo đang hình thành, AI tại Việt Nam đang bước vào giai đoạn “đặt nền móng”, nơi dữ liệu, hạ tầng và tư duy quản trị sẽ quyết định tốc độ và chiều sâu phát triển trong những năm tới.

1.837 Camera AI tại Hà Nội chính thức hoạt động giám sát giao thông.
Kết luận
Dữ liệu không chỉ là “mỏ dầu”, nó là nguồn lực sống, là tài sản chiến lược và là nền tảng của thời đại AI. Tuy nhiên, dữ liệu chỉ thực sự có giá trị khi được chuẩn bị, tổ chức, bảo vệ và kết nối với các hệ thống AI phù hợp. Các mô hình AI nền tảng như GPT hay Gemini về bản chất chỉ là công cụ. Điều tạo ra sức mạnh thực sự là khả năng doanh nghiệp và quốc gia biến dữ liệu thô thành tri thức, hành động và quyết định đúng đắn.
Đối với doanh nghiệp, AI không phải là món đồ công nghệ để khoe khoang, mà là trung tâm tự động hóa và tri thức, phục vụ hoạt động kinh doanh thực tế. Đối với quốc gia, dữ liệu và AI là trụ cột cho tăng trưởng kinh tế, an ninh và đổi mới sáng tạo.
Trong bối cảnh Việt Nam, cơ hội đang mở ra nhưng đi kèm thách thức rõ rệt. Dữ liệu và AI không còn là lựa chọn; chúng là yếu tố sống còn cho cạnh tranh trong thế kỷ 21. Những bước đi chiến lược hôm nay sẽ quyết định vị thế của doanh nghiệp và quốc gia trong tương lai không xa.
Đặng Vân Phúc
Chuyên gia công nghệ


 Nghị quyết 57-NQ/TW của Bộ Chính trị có 3 ý nghĩa lớn đối với lĩnh vực tự động hóa
Nghị quyết 57-NQ/TW của Bộ Chính trị có 3 ý nghĩa lớn đối với lĩnh vực tự động hóa