
Cơ sở của AI hiện đại là xác suất - thống kê
AI của thế kỷ XXI thường được kể như câu chuyện của GPU, dữ liệu lớn và những mạng nơ-ron “khổng lồ”. Nhưng nếu bóc lớp vỏ phần cứng và thuật toán, phần lõi của phần lớn hệ AI hôm nay lại là một ý tưởng rất cổ điển: làm việc với sự không chắc chắn. Mà đã nói đến không chắc chắn, ngôn ngữ tự nhiên nhất của toán học chính là xác suất; còn bộ công cụ để học từ dữ liệu và kiểm tra xem mình có tự tin quá đà hay không, chính là thống kê. [2,3,4] Nói thẳng: nhiều hệ AI hiện đại không “biết” theo nghĩa con người biết. Chúng học cách ước lượng xem dữ liệu có khả năng trông như thế nào, rồi đưa ra câu trả lời “hợp lý nhất” theo xác suất. Cách làm này vừa mạnh mẽ, vừa có một cái giá: nếu ta quên mất bản chất xác suất ấy, ta rất dễ ngộ nhận độ trôi chảy là mức độ đúng đắn. [2,3]
Khi thế giới mơ hồ, xác suất trở thành chiếc la bàn
Đời thật không vận hành theo kiểu “đúng/sai” sạch sẽ như sách giáo khoa. Ảnh chụp bị rung, chữ bị thiếu nét, giọng nói có tạp âm, câu hỏi của người dùng thì ngắn mà ý lại dài. Ngay cả những khái niệm tưởng chừng đơn giản như “mèo” cũng có vùng xám: mèo con, mèo bị che một phần, tượng mèo, tranh mèo.
Trong bối cảnh đó, AI muốn làm việc nghiêm túc phải trả lời được hai câu hỏi:
Nó đoán cái gì?
Và nó tự tin đến mức nào?
Xác suất giúp AI trả lời câu thứ hai một cách có hệ thống: thay vì phán “chắc chắn là mèo”, mô hình có thể nói “khả năng là mèo khoảng 0,93”, nghĩa là vẫn chừa một khoảng cho sai số và ngoại lệ. Thống kê bước vào để ta biết con số 0,93 ấy có đáng tin không, có bị “nổ tự tin” (overconfident) không, và khi đem ra dùng ngoài thực tế thì sai ở đâu, sai bao nhiêu.
Từ AI viết luật sang AI học từ dữ liệu: một bước ngoặt mang tính… thực dụng
Những thập niên đầu của AI từng đặt cược vào cách tiếp cận rất “truyền thống”: trí tuệ có thể mô tả bằng các luật rõ ràng kiểu “nếu - thì”. Cách này chạy tốt ở những bài toán có luật chặt (cờ vua, bài toán logic, chứng minh định lý nhỏ), nhưng nhanh chóng hụt hơi trước đời sống: ngoại lệ nhiều hơn “chính” lệ, và cái quan trọng nhất lại không nằm trong luật, mà nằm trong dữ liệu.
Học máy (machine learning) đổi câu hỏi. Thay vì hỏi: “Luật nào quyết định ảnh là mèo?”, ta hỏi: “Từ hàng triệu ảnh, mô hình nào ước lượng tốt nhất ranh giới giữa ‘mèo’ và ‘không mèo’?”. Nói theo ngôn ngữ xác suất, nhiều bài toán học máy là bài toán xấp xỉ phân bố của dữ liệu: dữ liệu xuất hiện “thường xuyên” theo kiểu nào, trường hợp hiếm trông ra sao và nhiễu thường nằm ở đâu.
Điều này giải thích vì sao AI hiện đại rất “khát” dữ liệu. Với dữ liệu ít, mô hình dễ nhầm tín hiệu với nhiễu; với dữ liệu nhiều, nó bắt đầu nhận ra thứ lặp lại bền vững. Quy luật số lớn không phải khẩu hiệu; nó là lý do nền móng khiến “dữ liệu lớn” trở thành dầu mỏ của AI.
Bayes: công thức của thói quen cập nhật niềm tin
Nếu phải chọn một công thức thâu tóm gọn tinh thần của AI hiện đại, định lý Bayes là ứng viên nặng ký. Nó mô tả cách ta cập nhật một niềm tin khi có thêm bằng chứng. [1,2]
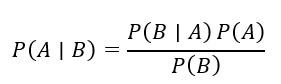
Trong đó là giả thuyết (ví dụ: “email là spam”), là bằng chứng quan sát (ví dụ: “email có cụm từ ‘khuyến mãi’, ‘nhận ngay’, ‘hoàn tiền’…”). Một hệ lọc thư rác kiểu Bayes không “đọc hiểu” theo kiểu con người; nó làm việc như một kế toán cẩn thận: cộng dồn bằng chứng, điều chỉnh niềm tin và đưa ra quyết định theo xác suất.
Bayes còn hữu ích ở chỗ nó buộc ta nghĩ theo cấu trúc: trước khi thấy dữ liệu, ta đã tin gì (prior)? dữ liệu này hợp với giả thuyết ấy đến đâu (likelihood)? và sau khi cập nhật, mức tin mới là bao nhiêu (posterior)? Nếu muốn AI “bớt bịa”, thói quen Bayes chính là một kiểu kỷ luật: không kết luận khi chưa đủ bằng chứng.
Phân phối xác suất: ngôn ngữ chung để tóm tắt dữ liệu phức tạp
Khi nói “dữ liệu”, ta đang nói tới một biển số liệu lộn xộn. Thống kê cần một ngôn ngữ để tóm tắt biển ấy thành vài thông tin cốt lõi: trung bình, độ lệch, độ phân tán, tần suất… và quan trọng hơn, “hình dạng” của sự biến thiên.
Đó là nơi các phân phối xác suất xuất hiện như một bộ từ điển cơ bản:
Phân phối chuẩn (Gaussian) thường được dùng để mô hình hóa sai số đo và nhiễu quanh một giá trị trung tâm. Nó giống một lời nhắc rằng nhiều thứ trong đời “dao động quanh mức bình thường”, và phần sai lệch lớn là hiếm.
Phân phối Bernoulli phù hợp với lựa chọn 0/1: có/không, đúng/sai, nhấp/không nhấp. Từ bài toán dự đoán một người có bấm vào quảng cáo hay không, đến câu hỏi “đường có trơn không”, Bernoulli xuất hiện khắp nơi.
Phân phối Poisson hay gặp khi ta đếm số sự kiện xảy ra theo thời gian: số cuộc gọi đến tổng đài trong một giờ, số lỗi hệ thống trong một ngày, số khách ghé cửa hàng trong một khung giờ.
Multinomial mở rộng Bernoulli sang nhiều lựa chọn rời rạc. Đặc biệt, nó gần gũi với mô hình ngôn ngữ: ở mỗi bước, mô hình cần chọn một token trong một “từ điển” rất lớn.
Bạn không cần nhớ tên gọi để dùng AI, nhưng hiểu rằng AI đang “nói chuyện” bằng phân phối xác suất sẽ giúp ta đặt kỳ vọng đúng: AI không đưa ra chân lý tuyệt đối; nó đưa ra một dự đoán có mức tin cậy.
Học máy: khi thống kê trở thành động cơ dự báo
Nhiều thuật toán học máy có thể nhìn như thống kê “đóng gói”. Hồi quy tuyến tính dự báo giá trị liên tục; hồi quy logistic biến phân loại thành bài toán ước lượng xác suất trong khoảng 0 đến 1. Nhưng dù tên gọi khác nhau, phần khó vẫn là phần cũ: làm sao để mô hình tổng quát hóa, tức là làm tốt trên dữ liệu mới, chứ không chỉ giỏi “học thuộc”.
Ở đây có một cuộc mặc cả kinh điển: độ chệch (bias) và phương sai (variance). Mô hình quá đơn giản thì bỏ sót cấu trúc (bias cao). Mô hình quá phức tạp thì dễ học thuộc dữ liệu huấn luyện (variance cao) và vấp khi ra đời thực. Trong tiếng nghề, đó là quá khớp (overfitting). [3]
Vì thế, người làm AI thường phải “siết kỷ luật” bằng điều chuẩn (regularization). Một cách viết gọn mục tiêu huấn luyện là: [1,3]
![]()
Trong đó là hàm mất mát (mô tả sai số dự đoán), còn là khoản phạt để tham số không phình to vô tội vạ. Nghe rất toán, nhưng bản chất rất đời: đừng tham quá. Đừng cố khớp mọi chi tiết nhỏ của dữ liệu cũ, hãy giữ một mức “vừa đủ” để còn đi đường dài.
Mô hình ngôn ngữ lớn: một cỗ máy ước lượng xác suất token [5,6]
Sự bùng nổ của các mô hình như ChatGPT khiến nhiều người nghĩ máy đang “tư duy”. Nhưng nhìn từ bên trong, một mô hình ngôn ngữ lớn (LLM) chủ yếu làm một việc: ước lượng xác suất token tiếp theo dựa trên ngữ cảnh.
![]()
Từ những điểm số thô (logits) cho toàn bộ từ điển, mô hình dùng hàm softmax để biến chúng thành một phân phối xác suất có tổng bằng 1:
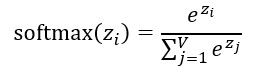
Với ngữ cảnh “Bầu trời có màu…”, mô hình có thể gán xác suất cao cho “xanh”, thấp hơn cho “nhiều mây”, rất thấp cho những từ vô nghĩa trong ngữ cảnh đó. Quá trình sinh văn bản là tự hồi quy: chọn một token, nối vào câu, rồi lặp lại.
Điều quan trọng là: LLM tối ưu hóa “đúng theo ngôn ngữ” trước, rồi mới “đúng theo sự thật” nếu nó có đủ dữ liệu và cơ chế kiểm chứng. Khi bạn hiểu được ưu tiên này, bạn sẽ hiểu vì sao LLM đôi khi trả lời trôi chảy mà vẫn sai. [10,11]
Núm vặn “decoding” và lý do cùng một câu hỏi lại cho nhiều đáp án
Một chi tiết thú vị: cùng một mô hình, chỉ cần đổi cách lấy mẫu (decoding), “tính cách” câu trả lời đã khác. Nếu luôn chọn token có xác suất cao nhất, câu chữ thường chắc tay nhưng dễ lặp và ít sáng tạo. Nếu lấy mẫu ngẫu nhiên, câu trả lời phong phú hơn nhưng cũng dễ trượt khỏi đường ray.
Trong thực hành, người ta hay dùng vài núm vặn quen thuộc:
Temperature làm phân phối nhọn hơn (thận trọng) hoặc phẳng hơn (phiêu lưu).
Top-k chỉ cho phép chọn trong k token có xác suất cao nhất để tránh rơi vào phần “đuôi” vô nghĩa.
Top-p (nucleus sampling) chọn tập nhỏ nhất các token có tổng xác suất đạt ngưỡng (ví dụ 0,9), thường cân bằng tốt giữa mạch lạc và đa dạng. [12]
Nhìn theo xác suất, đây không phải mẹo vặt. Đây là cách ta điều khiển mức rủi ro: muốn chắc tay thì hạ độ ngẫu nhiên; muốn sáng tạo thì nới biên.
“Ảo giác” của AI: khi xác suất tạo câu thắng sự thật của thế giới
Hiện tượng LLM “bịa mà nghe hợp lý” thường được gọi là ảo giác (hallucination). Cơ chế sâu xa không thần bí: mô hình được huấn luyện để tạo ra chuỗi từ có khả năng xuất hiện cao trong ngữ cảnh. Nếu ngữ cảnh thiếu dữ kiện, nó sẽ có xu hướng lấp chỗ trống bằng những mảnh ghép nghe hợp tai, giống như người kể chuyện ứng biến (improvise) hay “cương” khi không nhớ chi tiết. [10,11]
Bạn có thể xem LLM như một “thợ viết” rất lành nghề về nhịp câu, nhưng không tự động là “thợ kiểm chứng”. Nếu yêu cầu của ta là sự thật chính xác (pháp lý, y tế, tài chính), ta cần thêm cơ chế để buộc nó quay về với dữ liệu và bằng chứng.
Làm sao để AI chính xác hơn và giảm thiểu ảo giác
Muốn AI bớt ảo giác, không thể chỉ “nhắc nó trả lời đúng”. Cần thiết kế hệ thống theo kiểu làm nghề truyền thống: có tiêu chuẩn, có đối chiếu, có kiểm nghiệm, có trách nhiệm.
- Neo vào nguồn dữ liệu chuẩn (grounding/RAG). Thay vì để mô hình tự suy từ trí nhớ thống kê, ta cho nó truy xuất tài liệu nội bộ, cơ sở dữ liệu, hoặc nguồn đáng tin, rồi trả lời dựa trên trích dẫn/đoạn liên quan. Khi có “sổ cái” để đối chiếu, khả năng bịa giảm mạnh. [7]
- Bắt mô hình dùng công cụ kiểm chứng. Với câu hỏi có thể tính, tra cứu, hoặc kiểm tra (số liệu, ngày tháng, định nghĩa), hãy để hệ thống gọi công cụ: tìm kiếm trong kho, chạy truy vấn, tính toán, rồi mới viết câu trả lời. Người làm nghề gọi đây là “đo rồi mới cắt”. [13,14]
-Thiết kế vòng lặp tự kiểm (verification loop). Sau khi sinh câu trả lời, mô hình (hoặc một mô hình khác) sẽ kiểm tra lại: có mâu thuẫn nội bộ không, có khẳng định nào thiếu bằng chứng không, có con số nào vô lý không. Cách này giống biên tập: viết xong phải soát.
- Quản lý mức tự tin và hiệu chỉnh xác suất (calibration). Một mô hình tốt không chỉ đúng, mà còn biết mình có thể sai. Các thước đo (score) như Brier score giúp đánh giá việc “tự tin có đúng chỗ” hay không: [8,9]
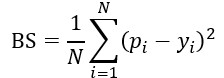
- Ở đây là xác suất dự đoán, là kết quả thực (0 hoặc 1). Điểm càng thấp, mô hình càng “biết lượng sức mình”.
- Giữ con người ở những điểm quyết định. Với nội dung ảnh hưởng lớn (hợp đồng, chẩn đoán, khuyến nghị đầu tư), cần có kiểm duyệt hoặc phê duyệt của người có chuyên môn. AI nên là “thợ phụ” tăng tốc, không phải người ký tên chịu trách nhiệm cuối.
- Đo lường và giám sát như vận hành một hệ thống kỹ thuật. AI dùng lâu sẽ gặp dữ liệu trôi (data drift), mô hình trôi (model drift). Nếu không theo dõi, chất lượng sẽ tụt mà không ai biết. Muốn bền, phải đo định kỳ, lưu log, kiểm thử hồi quy và cập nhật có kiểm soát.
Tóm lại: Giảm ảo giác không phải phép màu, mà là một chuỗi kỷ luật kỹ thuật - giống hệt cách người ta đảm bảo chất lượng trong sản xuất.
Tương quan và nhân quả: điểm mù dai dẳng của AI “học từ mẫu”
AI rất giỏi phát hiện tương quan: cái gì hay đi với cái gì. Nhưng tương quan không tự động là nhân quả. Nhầm hai khái niệm này dễ dẫn tới quyết định sai, đặc biệt trong y tế, tài chính và chính sách. [15]
Ví dụ: nếu thấy nhóm uống cà phê có tỷ lệ bệnh cao hơn, kết luận “cà phê gây bệnh” có thể sai vì một biến gây nhiễu (chẳng hạn hút thuốc) mới là nguyên nhân thật. Cà phê chỉ tình cờ đi cùng thói quen đó.
Thống kê cổ điển dạy ta thói quen nghiêm túc: kiểm soát biến gây nhiễu, thiết kế thí nghiệm, và không vội kết luận nhân quả từ dữ liệu quan sát. Đây là một điểm mà “tinh thần làm nghề” của thống kê vẫn rất đáng học trong thời AI.
Causal AI: từ “đoán theo mẫu” sang “hiểu theo cơ chế”
Causal AI (AI nhân quả) cố gắng mô hình hóa cơ chế tạo ra dữ liệu, không chỉ bắt chước mẫu xuất hiện. Thay vì hỏi “sắp tới thường xảy ra gì?”, nó hỏi “nếu tôi can thiệp thay đổi thì sẽ ra sao?”. [15]
Trong nhiều bài toán thực tế, câu hỏi đúng là câu hỏi can thiệp: tăng giá thì doanh thu đổi thế nào, thay phác đồ thì tỷ lệ khỏi bệnh ra sao, đổi quy trình thì tai nạn lao động giảm không. Khi AI tiến gần hơn tới ra quyết định, tư duy nhân quả sẽ là chiếc cầu nối quan trọng giữa dự báo và hành động.
Khi AI nuôi AI: câu chuyện “mất bản gốc” và nguy cơ sụp đổ mô hình
Internet đang đầy nội dung do AI tạo ra. Nếu mô hình đời sau học lại từ dữ liệu tổng hợp do mô hình đời trước sinh ra, ta có nguy cơ rơi vào vòng lặp giống như photocopy từ bản photocopy: mỗi lần sao lại, chi tiết mờ đi, độ đa dạng giảm, những trường hợp hiếm bị quên dần. [16]
Giải pháp nghe đơn giản nhưng lại rất “truyền thống”: ưu tiên dữ liệu gốc do con người tạo, ghi rõ nguồn gốc dữ liệu, lọc dữ liệu nhiễm nội dung tổng hợp khi cần, và xây kho dữ liệu sạch như xây thư viện. Với AI, dữ liệu không chỉ là nhiên liệu; dữ liệu là chất lượng.
Kết luận: AI càng hiện đại, càng cần nền móng cổ điển
AI hiện đại là một cỗ máy xác suất - thống kê được tăng lực bằng dữ liệu lớn và năng lực tính toán. Hiểu điều này giúp ta bớt ảo tưởng về “linh hồn trong máy”, và tập trung vào điều quan trọng hơn: dùng công cụ đúng chỗ, kiểm chứng đúng cách, và vận hành có kỷ luật.
Nếu phải chốt lại bằng một câu theo tinh thần làm nghề: AI có thể viết rất nhanh, nhưng sự thật vẫn cần được đo, kiểm và đối chiếu. Khi thực - ảo lẫn lộn, chính những thói quen cổ điển ấy mới là chiếc neo để công nghệ phục vụ con người.
Tài liệu tham khảo
[1] C. M. Bishop. Pattern Recognition and Machine Learning. Springer, 2006.
[2] K. P. Murphy. Probabilistic Machine Learning: An Introduction. The MIT Press, 2022.
[3] T. Hastie, R. Tibshirani, J. Friedman. The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2nd ed.). Springer, 2009.
[4] I. Goodfellow, Y. Bengio, A. Courville. Deep Learning. The MIT Press, 2016.
[5] A. Vaswani et al. Attention Is All You Need. NeurIPS, 2017. arXiv:1706.03762.
[6] T. B. Brown et al. Language Models are Few-Shot Learners. NeurIPS, 2020. arXiv:2005.14165.
[7] P. Lewis et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS, 2020. arXiv:2005.11401.
[8] C. Guo, G. Pleiss, Y. Sun, K. Q. Weinberger. On Calibration of Modern Neural Networks. ICML, 2017. arXiv:1706.04599.
[9] G. W. Brier. Verification of Forecasts Expressed in Terms of Probability. Monthly Weather Review, 78(1), 1950. DOI:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2.
[10] Z. Ji et al. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 2023. DOI:10.1145/3571730. (Bản thảo arXiv:2202.03629, 2022).
[11] L. Huang et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv:2311.05232, 2023.
[12] A. Holtzman et al. The Curious Case of Neural Text Degeneration. arXiv:1904.09751, 2019.
[13] S. Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629, 2022 (ICLR 2023).
[14] T. Schick et al. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761, 2023.
[15] J. Pearl. Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press, 2009.
[16] I. Shumailov et al. The Curse of Recursion: Training on Generated Data Makes Models Forget. arXiv:2305.17493, 2023.
Đặng Mạnh Phổ (tổng hợp, có sử dụng công cụ AI hỗ trợ)

 Tổng Bí thư, Chủ tịch nước Tô Lâm: Chuyển mạnh từ cứu trợ tình thế sang chủ động phòng ngừa
Tổng Bí thư, Chủ tịch nước Tô Lâm: Chuyển mạnh từ cứu trợ tình thế sang chủ động phòng ngừa

 Công tác nhân đạo phải trở thành một bộ phận của chiến lược phát triển con người
Công tác nhân đạo phải trở thành một bộ phận của chiến lược phát triển con người

 Phát biểu chỉ đạo của Tổng Bí thư, Chủ tịch nước Tô Lâm tại Đại hội toàn quốc Hội Chữ thập đỏ Việt Nam
Phát biểu chỉ đạo của Tổng Bí thư, Chủ tịch nước Tô Lâm tại Đại hội toàn quốc Hội Chữ thập đỏ Việt Nam
 Phó Thủ tướng Thường trực chỉ đạo tháo gỡ vướng mắc cho các dự án điện gió ở tỉnh Lâm Đồng
Phó Thủ tướng Thường trực chỉ đạo tháo gỡ vướng mắc cho các dự án điện gió ở tỉnh Lâm Đồng
































