
Cải thiện phát hiện Deepfake thông qua đưa vào nhận thức đa dạng nhân khẩu học
Deepfake, công nghệ cho phép tạo ra những video và hình ảnh mà trong đó người khác dường như nói hoặc làm những điều mà họ chưa từng thực hiện, đã trở nên tinh vi hơn bao giờ hết.
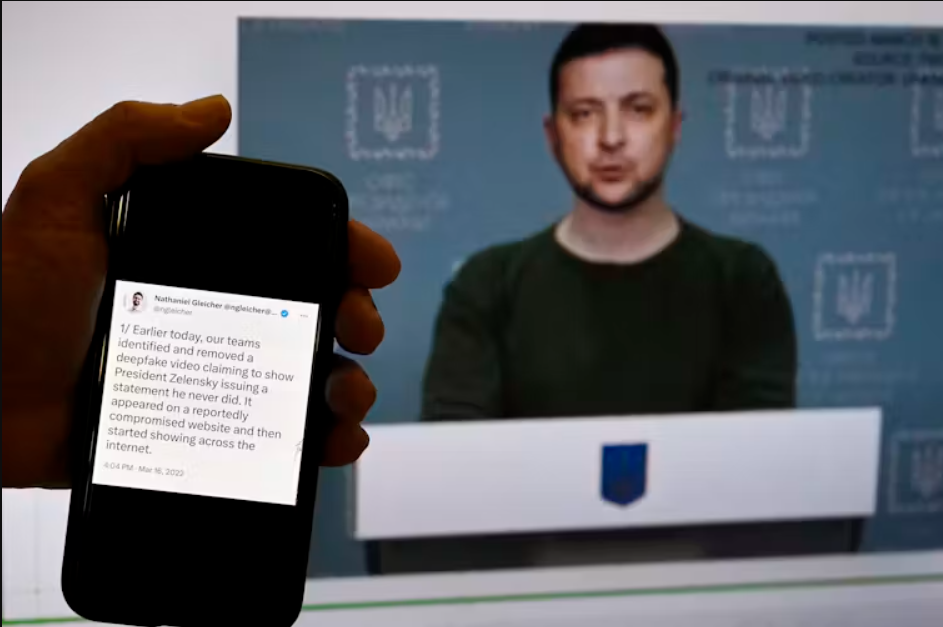
Những ví dụ gần đây, chẳng hạn như hình ảnh khỏa thân của Taylor Swift , bản ghi âm Tổng thống Joe Biden nói với người dân New Hampshire không bỏ phiếu và video Tổng thống Ukraine Volodymyr Zelenskyy kêu gọi quân đội hạ vũ khí.
Mặc dù đã có những công cụ được phát triển để phát hiện deepfake, nhưng nghiên cứu chỉ ra rằng sự thiên lệch trong dữ liệu huấn luyện có thể dẫn đến việc một số nhóm nhân khẩu học bị nhắm mục tiêu không công bằng. Để giải quyết vấn đề này, nhóm nghiên cứu của chúng tôi đã tiến hành khám phá những phương pháp mới nhằm cải thiện cả độ chính xác và tính công bằng trong phát hiện deepfake.
Chúng tôi đã sử dụng một tập dữ liệu lớn chứa các khuôn mặt giả mạo để đào tạo các thuật toán học sâu, dựa trên nền tảng Xception – một trong những thuật toán hiện đại phổ biến nhất trong phát hiện deepfake, với độ chính xác cơ bản đạt 91,5%.
Cải thiện phát hiện Deepfake thông qua đưa vào nhận thức đa dạng nhân khẩu học
Trong nghiên cứu của mình, chúng tôi đã phát triển hai phương pháp phát hiện deepfake. Phương pháp đầu tiên tập trung vào việc gán nhãn dữ liệu theo giới tính và chủng tộc, nhằm giúp thuật toán hiểu rõ hơn về sự đa dạng nhân khẩu học, từ đó giảm thiểu sai sót đối với những nhóm chưa được đại diện đầy đủ. Phương pháp thứ hai lại tìm cách cải thiện tính công bằng mà không sử dụng nhãn nhân khẩu học, bằng cách chú trọng vào các đặc điểm mà mắt người không nhìn thấy được.
Kết quả cho thấy, phương pháp đầu tiên mang lại hiệu quả tốt nhất. Độ chính xác của thuật toán đã tăng lên 94,17%, một mức tăng đáng kể so với mức cơ bản, đồng thời cải thiện tính công bằng – yếu tố cốt lõi trong nghiên cứu của chúng tôi.
Chúng tôi tin rằng việc đảm bảo tính chính xác và công bằng trong các thuật toán phát hiện deepfake là vô cùng quan trọng để công chúng có thể tin tưởng vào công nghệ trí tuệ nhân tạo. Khi các mô hình ngôn ngữ lớn như ChatGPT có thể “ảo giác”, việc bảo trì thông tin chính xác là điều cần thiết để giữ vững lòng tin và an toàn cho người dùng. Nếu không có những công cụ phát hiện deepfake hiệu quả, tác động tiêu cực của chúng có thể làm suy yếu sự chấp nhận của xã hội đối với AI.
Nghiên cứu của chúng tôi không chỉ tập trung vào việc cân bằng dữ liệu mà còn đề xuất một phương pháp thiết kế thuật toán sâu sắc hơn, coi tính công bằng về mặt nhân khẩu học như một yếu tố trung tâm. Chúng tôi hy vọng rằng thông qua những cải thiện này, công nghệ phát hiện deepfake sẽ ngày càng trở nên mạnh mẽ và chính xác hơn, góp phần bảo vệ mọi nhóm nhân khẩu học khỏi những tác động tiêu cực của công nghệ.
 Google mở rộng công cụ xác minh độ tuổi Play Store trên toàn cầu: Ý nghĩa đối với người dùng
Google mở rộng công cụ xác minh độ tuổi Play Store trên toàn cầu: Ý nghĩa đối với người dùng
 Zuckerberg trình bày về tiến tính lưỡng dụng năng lực AI của Meta: Bán gì và giữ lại gì
Zuckerberg trình bày về tiến tính lưỡng dụng năng lực AI của Meta: Bán gì và giữ lại gì
 Google tiếp tục hé lộ cái nhìn mới về tính năng Pixel Glow trong đoạn teaser mới của Pixel 11 Pro
Google tiếp tục hé lộ cái nhìn mới về tính năng Pixel Glow trong đoạn teaser mới của Pixel 11 Pro
 Google Pixel Watch 5 bất ngờ xuất hiện trên một ứng dụng chính thức của Google trước thềm sự kiện ra mắt dự kiến
Google Pixel Watch 5 bất ngờ xuất hiện trên một ứng dụng chính thức của Google trước thềm sự kiện ra mắt dự kiến

 iPhone Ultra có thể chỉ là một trong số hàng loạt sản phẩm hoàn toàn mới của Apple vào mùa thu này
iPhone Ultra có thể chỉ là một trong số hàng loạt sản phẩm hoàn toàn mới của Apple vào mùa thu này
 Bản cập nhật ứng dụng Google Clock giúp tính năng đếm ngược và bấm giờ trở nên hữu ích, dễ theo dõi hơn
Bản cập nhật ứng dụng Google Clock giúp tính năng đếm ngược và bấm giờ trở nên hữu ích, dễ theo dõi hơn
 Thuê bao YouTube Premium sẽ nhận được một đặc quyền tuyệt vời mới bắt đầu từ năm sau
Thuê bao YouTube Premium sẽ nhận được một đặc quyền tuyệt vời mới bắt đầu từ năm sau
 "Điểm mù" trên Google Maps đã được khắc phục: Dữ liệu giao thông chính thức trở lại
"Điểm mù" trên Google Maps đã được khắc phục: Dữ liệu giao thông chính thức trở lại






























