Ứng dụng thành quả của VLSP và những vấn đề tồn tại trong kết nối dữ liệu và hạ tầng
VLSP là tên viết tắt của CLB Xử lí ngôn ngữ và tiếng nói tiếng Việt thuộc Hội Tin học Việt Nam (VAIP). Phát biểu trong buổi Tọa đàm ICT 2020 “Chuyển đổi số: Cơ hội và thách thức”, ông Nguyễn Việt Cường - Tổng giám đốc của Công ty INT2 đã chỉ ra một số vấn đề còn tồn tại trong công cuộc Chuyển đổi số.
- Tổng đài nhân tạo: Xu hướng chuyển đổi số trong lĩnh vực Chăm sóc khách hàng tại Việt Nam
- CMC: Hướng tới tương lai số – Tầm nhìn và sứ mệnh
- Nguyên lý cái thùng gỗ và Chuyển đổi số phải bắt đầu từ đâu?
- Chính phủ chỉ đạo các bộ, tỉnh tăng chi tiêu cho chuyển đổi số
- Chuyển đổi số: Học, vận dụng công nghệ chứ không đuổi theo công nghệ
- Tọa đàm ICT 2020 “Chuyển đổi số: Cơ hội và Thách thức”
Trước đó, Công nghệ và Đời sống đã đăng tải bài viết Tổng đài nhân tạo: Xu hướng chuyển đổi số trong lĩnh vực Chăm sóc khách hàng tại Việt Nam nói về cơ hội và thách thức của những công ty công nghệ trong nước, phần mềm mới của Công Ty (Vbee) và những “bước đi” của Tập đoàn Công nghệ CMC trong bài CMC: Hướng tới tương lai số – Tầm nhìn và sứ mệnh. Thì trong bài viết này, chúng ta sẽ cùng nhận định rõ hơn về thành quả của VLSP. Đồng thời chỉ rõ những vấn đề còn tồn tại trong kết nối dữ liệu và hạ tầng qua bài tham luận của đại diện Công ty CP Công nghệ chọn lọc thông tin (InfoRe) và Công ty TNHH Tích hợp thông minh (INT2).
Vừa qua, khi bùng phát đợt 2 dịch COVID-19 hồi đầu tháng 3/2020, InfoRe và INT2 đã được huy động tham gia xử lí và phân tích dữ liệu tại Tổ thông tin đáp ứng nhanh, trực thuộc Ban chỉ đạo Quốc gia Phòng, chống dịch COVID-19.
Tại tổ thông tin này, InfoRe và INT2 đã xử lí, phân tích dữ liệu để hỗ trợ công tác dịch tễ như: Truy vết và lập mô hình xác suất liên hệ F0, F1, F2; Tham gia xây dựng, chuẩn bị dữ liệu đầu vào cho các mô hình dự báo nguy cơ cho các tỉnh thành và toàn quốc để hỗ trợ quá trình ra quyết định; Xây dựng và cập nhật liên tục trang web biểu diễn thông tin dịch.

Toàn cảnh buổi Tọa đàm ICT 2020 “Chuyển đổi số: Cơ hội và thách thức” do Hội Tin học Việt Nam tổ chức ngày 3/7 vừa qua.
Cũng tại thời điểm này, rất nhiều công cụ và phương pháp xử lí dữ liệu do InfoRe và INT2 đã tích luỹ trong thực tế sản xuất kinh doanh thời gian qua cũng như hơn 10 năm tham gia các dự án VLSP được ứng dụng một cách triệt để. Cụ thể, như các vấn đề liên quan đến chuẩn hoá thông tin đầu vào, bóc tách thông tin từ tờ khai y tế, xử lí tích hợp thông tin từ nhiều nguồn, từ nhiều ngôn ngữ khác nhau. Mục tiêu là để truy vết dịch tễ nhanh nhất có thể và đưa ra chỉ số nguy cơ sát với thực tế.
Để có góc nhìn rõ hơn, ông Nguyễn Việt Cường Tổng giám đốc của INT2 kiêm đồng sáng lập InfoRe đưa ra dẫn chứng: “Những ứng dụng và phương pháp xử lý dữ liệu trong dịch COVID-19 của chúng tôi được ví như lý thuyết thùng gỗ mà ông Nguyễn Huy Dũng – Cục trưởng Cục Tin học hóa (Bộ TT-TT) đã nêu trước đó. Chúng tôi chính là đội ngũ bên trong cùng nhất và sử dụng những thông tin có thể nói là rất cốt lõi nhất của Chính phủ điện tử để hỗ trợ cho dịch tễ. Cũng chính từ đấy, chúng tôi mới thấy được rất nhiều vấn đề còn tồn tại trong quá trình bắt nhịp với Chuyển đổi số của các doanh nghiệp, đơn vị”.
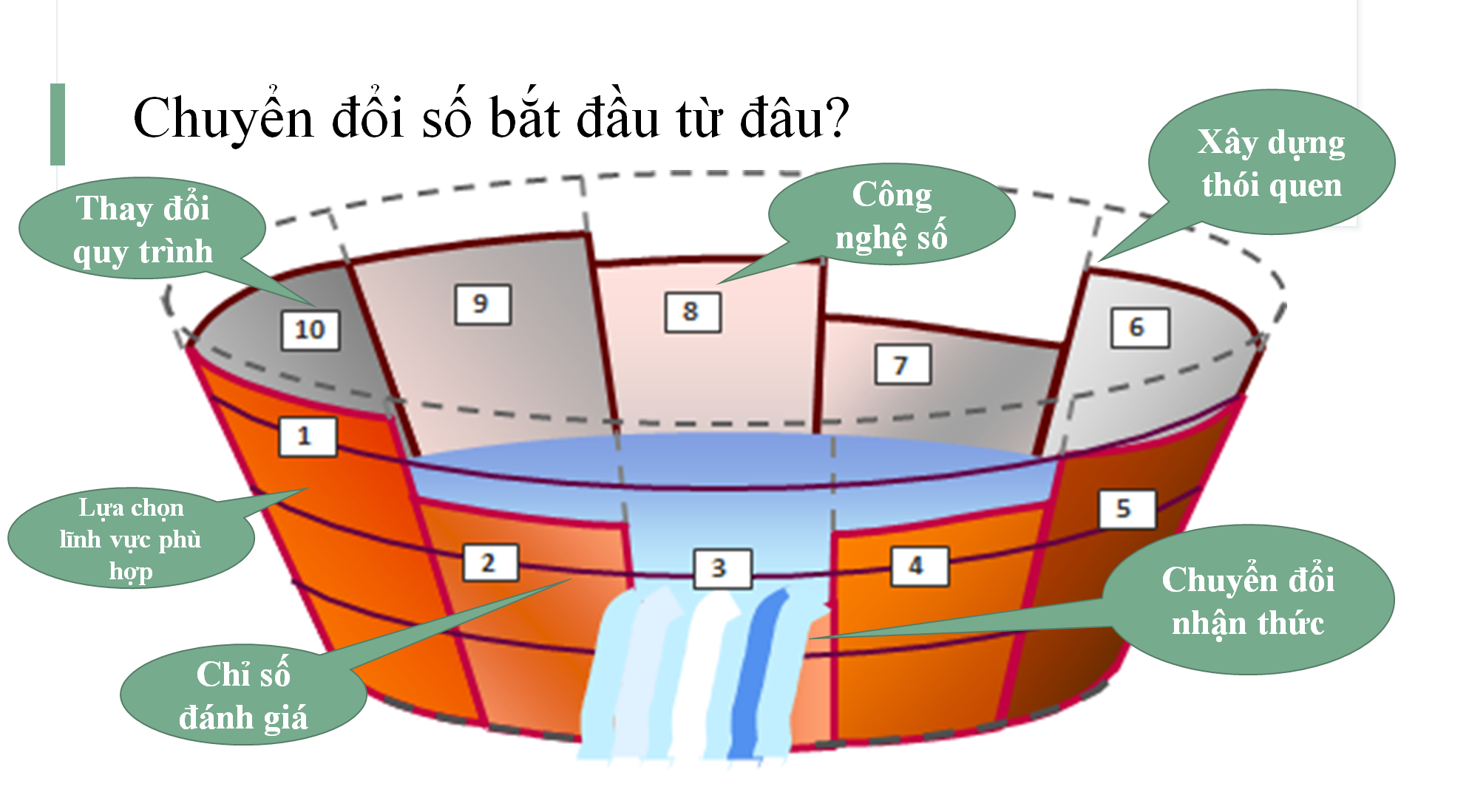
Nguyên lý cái thùng gỗ.
Ngoài ra, ông Nguyễn Việt Cường còn cho rằng cần phải đẩy nhanh, mạnh hơn nữa quá trình chuyển đổi số, đặc biệt là ở những cơ sở dữ liệu quan trọng của quốc gia như cơ sở dữ liệu định danh. Khi chúng ta mở cửa trở lại, chắc chắn công tác dịch tễ sẽ rất vất vả và nếu thiếu đi sự hỗ trợ của công nghệ thông tin mà đặc biệt là công nghệ phân tích dữ liệu lớn thì hiệu quả sẽ giảm đi nhiều lần và hậu quả là vô cùng lớn.
Từ thực tế đó, ông Nguyễn Việt Cường cho rằng quá trình xử lí phân tích thông tin, một công cụ trọng yếu trong quá trình chuyển đổi số, sẽ bao gồm 5 bước cơ bản như:
- Thu thập, bóc tách và chuẩn hoá thông tin đầu vào.
- Phân loại và kết nối thông tin.
- Lưu trữ và xử lí thông tin.
- Phân tích thông tin.
- Biểu diễn và phân tích kết quả.
Dựa trên cơ sở các thành phần đó, cùng với những kinh nghiệm thực tế quý báu có được trong thời gian tình nguyện tại tổ công tác, đại diện ho InfoRe và INT2 ông Nguyễn Việt Cường đã đưa ra một số kiến nghị.
Thứ nhất về thu thập, bóc tách và chuẩn hoá thông tin: Việt Nam tuy đã có nhiều năm tin học hóa và chuyển hóa số liệu. Tuy nhiên, giữa các cơ sở dữ liệu tồn tại sự thiếu nhất quán, không tuân theo tiêu chuẩn biểu diễn thông tin. Do đó, khi thống nhất các cơ sở dữ liệu thì dẫn đến việc không hợp nhất được một cách mặc định theo chuẩn quốc gia.
Ví dụ đơn giản như tên quốc gia hay ngay cả tên tỉnh/thành phố Việt Nam được viết theo quy tắc không thống nhất giữa các CSDL. Trong khi đó, thế giới đã có các chuẩn ISO để kí hiệu tên nước bằng 2 kí tự, 3 kí tự, tên đầy đủ; Việt Nam cũng có các quy định về tên định danh nhưng các đơn vị triển khai không hề tuân theo.
Do đó, các cơ quan chức năng cần nhanh chóng hiện thực hoá và phổ biến rộng rãi các cơ sở dữ liệu thống nhất, mở, đặc biệt là phổ cập đến các doanh nghiệp và sinh viên khối ngành CNTT. Tạo sẵn các hệ thống thư viện lập trình mở hoặc API cung cấp các thông tin và hàm chuẩn hoá căn bản, thống nhất.

Ông Nguyễn Việt Cường Tổng giám đốc của INT2 kiêm đồng sáng lập InfoRe phát biểu tại buổi Tọa đàm ICT 2020 “Chuyển đổi số: Cơ hội và thách thức”.
Thứ hai về mặt phân loại và kết nối thông tin: Hầu hết các hệ thống đều chưa có các yếu tố phân loại ngữ nghĩa của thông tin để trợ giúp cho quá trình xử lí tự động, tức là giúp máy hiểu được đoạn dữ liệu này có ý nghĩa gì, chức năng gì. Thậm chí nhiều lập trình viên ở Việt Nam cũng rất thông thạo, nhưng không phải dùng cho mục đích xử lí thông tin tự động của chính mình, mà để giúp các hệ thống của Google, Facebook hiểu được ý nghĩa của các từ trong trang web, với mục đích là để tối ưu hoá tìm kiếm, SEO.
Đây cũng là một nhiệm vụ của các thành viên trong cộng đồng VLSP để tự động hoá quá trình này, mà từ chuyên môn gọi là semantic role labeling.
Từ thực tế trên, InfoRe và INT2 đã đưa ra kiến nghị tới cơ quan chức năng cần huy động các doanh nghiệp tiến hành bản địa hoá các cây phân loại thông tin và mở ra cho cộng đồng dùng chung.
Thứ ba về lưu trữ và xử lí thông tin: Các hệ thống lưu trữ và xử lí chưa thực sự sẵn sàng để có thể huy động khi cần giải quyết bài toán cấp quốc gia. Việc huy động của Tổ công tác là khó khăn và chậm trễ với lượng tài nguyên chỉ được một phần so với yêu cầu. Các hệ thống tính toán và lưu trữ đa phần là dạng truyền thống, tập trung, không phù hợp với các công nghệ xử lí phân tán hiện đại cũng như các yêu cầu về hiệu năng tính toán.
Chính bởi vậy, các tập đoàn lớn cần có cơ chế đầu tư vào các công nghệ xử lí phân tán thế hệ mới với các hạ tầng sẵn sàng và có thể tham gia đóng góp một phần cho các nhiệm vụ quốc gia khi cần thiết.
Thứ tư về kĩ thuật phân tích thông tin: Trên thực tế trong đợt dịch Covid vừa qua, InfoRe và INT2 đã huy động một số đơn vị tham gia cùng. Thế nhưng, khả năng thực chiến của các cơ sở đào tạo, công ty công nghệ còn rất “non”.
Vì vậy cần đẩy mạnh sự kết hợp giữa nhà trường và doanh nghiệp trong đào tạo ở các lĩnh vực mới phục vụ quá trình chuyển đổi số quốc gia. Thời lượng cho sinh viên đi thực tập cần nhiều hơn; tỉ lệ giảng viên các khoá ngắn hạn đến từ khối doanh nghiệp cần được tăng cường; đẩy mạnh hơn mô hình cơ quan nhà nước làm trung gian đảm bảo việc hợp tác giữa doanh nghiệp và cơ quan nghiên cứu từ chất lượng sản phẩm đến giải ngân.
Cuối cùng về biểu diễn và phân tích kết quả: Việc tham gia của chuyên gia của lĩnh vực là tối cần thiết. Mọi phân tích thông minh sẽ gần như vô nghĩa nếu không có sự kết hợp này, mà trước là để đặt bài toán đúng và sau là hiểu được kết quả đầu ra.
Trong đợt tham gia xử lí và phân tích dữ liệu tại Tổ thông tin đáp ứng nhanh, InfoRe và INT2 đã làm việc trực tiếp cùng các giáo sư đến từ Viện Vệ sinh Dịch tễ Trung ương, Trường ĐH Y Hà Nội, Trường ĐH Y tế Công cộng và thấy được sự tương đồng trong nghiên cứu khoa học giữa hai lĩnh vực tưởng chừng không liên quan là phân tích dịch tễ và phân tích dữ liệu lớn trên mô hình đồ thị. Hai bên bổ trợ cho nhau và cùng thúc đẩy nhanh công tác phòng, chống dịch COVID-19.
Thế nhưng, hiện nay có một thực trạng của việc các startup công nghệ, hoặc bộ phận công nghệ tiên phong của các tập đoàn chạy theo các mô hình trí tuệ nhân tạo được công khai tràn lan trên Internet, đưa về chạy, ra một số kết quả, rồi công bố tôi tốt, ví dụ như mô hình AI của chúng tôi chuẩn đoán viêm phổi tốt hơn bác sĩ, v.v...
Tuy nhiên, phần lớn đó là các mô hình blackbox, kết quả tốt hơn về mặt thống kê, tỉ lệ dương tính giả hoặc âm tính giả vẫn ở xa so với chuyên gia. Và thực tế là các mô hình này hoạt động hiệu quả nhất khi được sử dụng dưới dạng hệ hỗ trợ quyết định cho chuyên gia.
Trước thực trạng đó, đại diện cho InfoRe và INT2 ông Nguyễn Việt Cường đưa ra đề xuất rằng các cơ quan chức năng cần học theo các nước phát triển, sớm nghiên cứu và ban hành các tiêu chuẩn về triển khai ứng dụng AI. Các tiêu chuẩn này đã được Nhật Bản và Hoa Kỳ công bố gần đây.
|
Câu lạc bộ Xử lý Ngôn ngữ và Tiếng nói tiếng Việt (Vietnamese Language and Speech Processing - VLSP) được các thành viên tự nguyện thành lập trên cơ sở tiếp thu và chia sẻ các tư tưởng của cộng đồng ngôn ngữ học tính toán thế giới. Câu lạc bộ ra đời với mục đích trở thành nơi kết nối các nhóm nghiên cứu, phát triển về xử lý tiếng Việt, để có tiếng nói chung tham gia vào các hoạt động đẩy mạnh sự phát triển của nghiên cứu và ứng dụng trong lĩnh vực Xử lý ngôn ngữ tự nhiên nói riêng và trí tuệ nhân tạo nói chung ở Việt Nam cũng như trên thế giới. Công ty cổ phần Công nghệ Chọn lọc Thông tin (INFORE) được thành lập vào tháng 4/2012 bởi các thành viên trẻ cùng có đam mê và kiến thức trong ngành Công nghệ thông tin (ICT) với mục tiêu thu hẹp khoảng cách giữa nghiên cứu và ứng dụng, giữa học thuật và thực tiễn. Hiện tại, công ty đang phát triển hệ thống SMCC (Social Media Command Center - Trung tâm điều phối tương tác truyền thông trên mạng xã hội) với các dòng sản phẩm hoạt động kết hợp giữa các công nghệ phân tích, thu thập dữ liệu và xử lý, giải quyết vấn đề, giúp các thương hiệu, doanh nghiệp hoặc cá nhân tương tác với cộng đồng mạng xã hội theo các chiến lược, cách thức an toàn, nhanh chóng, hiệu quả, chính xác và ổn định nhất. |
Thùy Dung

 Hơn 99 triệu thuê bao đã được xác thực, 12 triệu thuê bao bị tạm dừng một chiều
Hơn 99 triệu thuê bao đã được xác thực, 12 triệu thuê bao bị tạm dừng một chiều
 Đề xuất thu nhập tới 300 triệu đồng/tháng cho Tổng công trình sư phát triển công nghệ chiến lược
Đề xuất thu nhập tới 300 triệu đồng/tháng cho Tổng công trình sư phát triển công nghệ chiến lược